Chapter 2 Introducción al Big Data
2.1 Definiendo al Big Data
De forma simple el Big Data se define como:
\[DATA>RAM\]
O de forma mas literal “cualquier cosa demasiado grande para caber en su computadora.”
La Asociación Americana de Investigación de Opinión Pública menciona: “El término” Big Data “es una descripción imprecisa de un conjunto rico y complicado de características, prácticas, técnicas, cuestiones éticas y resultados, todos asociados con los datos.”
2.2 Las 5 V en el Big Data
- Velocidad
- Volumen
- Valor
- Variedad
- Veracidad
2.3 Ciclo de vida de un proyecto de análisis de datos
Se pueden identificar 4 fases:
- Clarify: (Clarificar) Llegar a familiarizarse con los datos
- Develop: (Desarrollar) Crear un modelop de trabajo
- Productize: (Producir) Automatizar e integrar
- Publish: (Publicar) Socializar
Estas fases pueden contener nodos adicionales según el proyecto:
- Subset: Extraer los datos a explorar, los datos de trabajo
- Clarify: (Clarificar) Llegar a familiarizarse con los datos
- Develop: (Desarrollar) Crear un modelop de trabajo *. Scale Up: Generalizar a la base de datos completa
- Productize: (Producir) Automatizar e integrar
- Publish: (Publicar) Socializar
Otros ciclos de trabajo puedes ser:
- Identificar el problema
- Diseño del requerimiento de datos
- Procesar los datos
- Desarrollo del análisis sobre los datos
- Visualizar los datos
2.4 Inferencia y Big Data
El objetivo de la inferencia es poder decir algo de la población objetivo a partir de la información disponibles. Se debe tener en cuenta los tipos de estudio provenientes; ya sean de encuestas probabilísticas, diseño experimentales o estudios de observación. Se debe estar seguro de la calidad de la base de datos proveniente, ya sean estos los errores de muestreo, procesos de calibración, ponderación, post estratificación en el caso de muestreo o el propensity score y la estratificación principal para reparar diseño experimentales rotos.
Se puede distinguir tres metas en el proceso de inferencia:
- Descriptivo
- Causal
- Predictivo
2.4.1 Descriptivo
La estadística descriptiva puede ser; (1) a un nivel simple de descripción de una base de datos sin la búsqueda de querer expandir los resultados (registros administrativos, censos, estudios de observación) o (2) para encuestas probabilisticas, realizar las estimaciones de la muestra con sus respectivos errores muestrales y a partir de estas estimaciones describir a la población
Ejemplo: El INE estima a partir de la EH-2018 que la incidencia de pobreza moderadara en Bolivia para el 2018 alcanza el …%
Ejemplos como este muestra que el propósito es puramente descriptivo en cuanto a la pobreza.
2.4.2 Causal
Muchos investigadores buscan explorar hipótesis, aveces originadas en la teoría o en alguna relación observada de forma empírica, con la idea central de permitir la inferencia causal.
La data para esto proviene de diseños experimentales o fuertes estudios no experimentales (cuasi-experimentales), el interés de estos estudios es principalmente encontrar el efecto de de una variable entre otra.
\[X \rightarrow Y\] Aspecto que es logrado fácilmente mediante los diseños experimentales. En este tipo de estudio el componente descriptivo no es tan importante como el método para identificar la causalidad. Es importante diferenciar en este punto la causalidad de la correlación.
Ejemplo: (3ie) Este informe se basa en un estudio de Dupas, Duflo y Kremer que se realizó en colaboración con el gobierno de Ghana. El estudio examinó los impactos a mediano plazo de otorgar becas de cuatro años a estudiantes que no podían matricularse en escuelas secundarias superiores (SHS) debido a limitaciones financieras. Los investigadores encontraron que el programa de becas tuvo un impacto significativo en el logro educativo y las habilidades cognitivas, particularmente entre las niñas. El programa también tuvo un mayor impacto en las tasas de finalización de SHS de las niñas en términos porcentuales.
Ejemplo: UDAPE el 2013 realizó el calculo del impacto de la renta dignidad en Bolivia empleando el método de regresión discontinua un método cuasi-experimental.
Una de las debilidades principales de estos estudios es la falta o poca de validez externa, es decir, es difícil poder generalizar los resultados.
- Métodos cuasi-experimentales
- Diferencia en diferencia
- Propensity Score Matching (PSM) Probit.
- Variables instrumentales
- Modelos estructurales
- Regresión Discontinua.
2.4.3 Predictivo
El pronóstico o predicción tiene un rol diferenciado según la ciencia de aplicación, teniendo un rol significativo dentro de las estadística oficiales, principalmente en lo social (proyecciones poblacionales) y económico (indicadores macroeconómicos), principalmente para hacedores de política, gobernantes y empresarios. Similar a En la configuración de inferencia causal, es de suma importancia que conozcamos el proceso que generó los datos, y podemos descartar cualquier mecanismo de selección sistemática desconocido o no observado.
Ejemplo: El Institute of Global Health, Faculty of Medicine, University of Geneva tiene una página web que realiza pronosticos por país para los casos de COVID-19. Enlace
2.5 Calidad de dato y Big Data
La mayoría de los datos en el mundo real son ruidosos, inconsistentes y adolecen de valores perdidos, independientemente de su origen. Incluso si la recopilación de datos es barata, los costos de crear datos de alta calidad a partir de la fuente (limpieza, conservación, estandarización e integración) son considerables. La calidad de los datos se puede caracterizar de múltiples maneras:
- Precisión: ¿qué tan precisos son los valores de los atributos en los datos?
- Integridad: ¿están completos los datos?
- Consistencia: ¿Cuán consistentes son los valores en y entre las bases de datos?
- Puntualidad: ¿qué tan oportunos son los datos?
- Accesibilidad: ¿están disponibles todas las variables para el análisis?
Los cientistas de datos tienen décadas de experiencia en la transformación de datos desordenados, ruidosos y no estructurados en un conjunto de datos bien definido, claramente estructurado y probado en calidad. El pre procesamiento es un proceso complejo y que lleva mucho tiempo porque es práctico: requiere juicio y no puede automatizarse de manera efectiva. Un flujo de trabajo típico comprende múltiples pasos desde la definición de datos hasta el análisis y termina con el filtrado. Es difícil exagerar el valor del pre-procesamiento para cualquier análisis de datos, pero esto es particularmente cierto en big data. Los datos deben analizarse, estandarizarse, no duplicarse y normalizarse.
- Análisis (parsing): Exploración de datos
- Estandarización (Standardization): Identificar variables que requieren transformación y ajustes.
- Duplicación: Consiste en eliminar registros redundantes
- Normalización (Normalization): Es el proceso de garantizar que los campos que se comparan entre archivos sean lo más similares posible en el sentido de que podrían haber sido generados por el mismo proceso. Como mínimo, se deben aplicar las mismas reglas de estandarización a ambos archivos.
2.6 Captura y preservación
Se refiere al proceso de obtener la información de las distintas fuentes posibles y luego pasar a un proceso de preservación.
2.6.1 Fuentes convencionales
Estas están basadas en la información que se distribuye de forma tradicional mediante bases de datos estructuradas, normalmente estas las distribuyen instituciones con amplios conocimientos en la gestión de bases de datos, para el caso de Bolivia se puede citar algunas:
- Instituto Nacional de Estadística
- SNIS
- UDAPE
- Geoboliva
- Ministerios …
2.6.2 Datos web y APIs
Se refiere a la captura y uso de la información que se genera en espacios digitales, web, redes sociales, etc.
Referirse al capítulo 3 de scraping web, estos son los mecanismos para extraer información en internet
2.6.3 Record Linkage
Se refiere al proceso de concatenar o unir observaciones dispuestas en múltiples bases de datos.
- Puede ser usado para compensar la falta de información
- Se usa para crear estudios longitudinales
- Se pueden armar seudo-paneles
Esto permite mejorar la cobertura (append), ampliar las temáticas de estudio (merge).
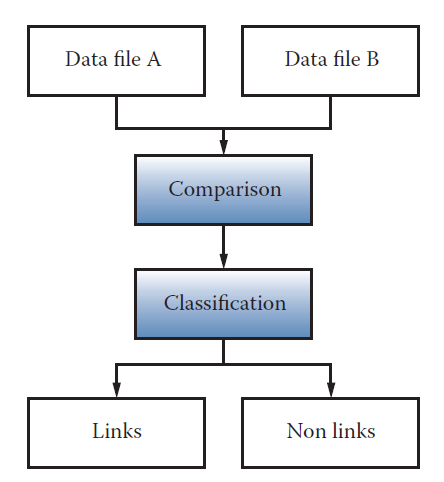
Pre-procesamiento
- Matching: Une información a partir de una clave, existen muchos problemas con claves tipo texto.
- Aproximaciones a reglas para hacer math: Definir criterios para posibilitar el match basados en reglas, distancias cercanas, etc.
- Match basados en probabilidad: Fellegi–Sunter method
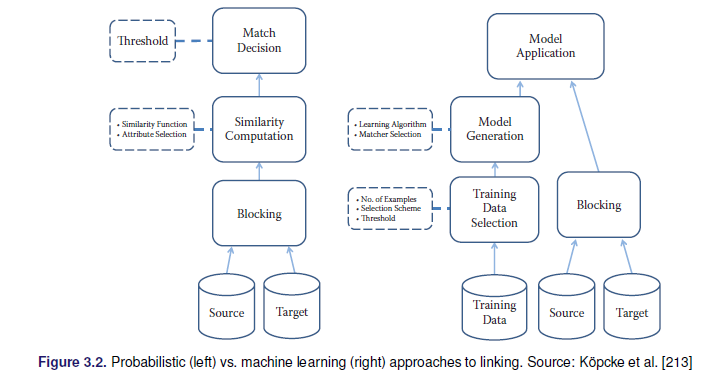
2.6.4 Bases de datos
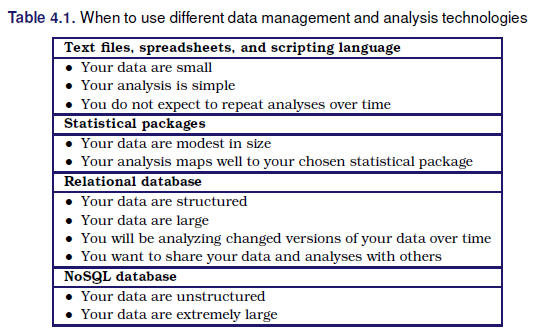
Una vez que los datos fueron recolectados y enlazados entre diferentes fuentes, es necesario guardar la información. Ahora se discute las alternativas para guardar la información.
- DBMS (databasemanagement systems) Sistema de gestión de base de datos: Decidir que herramienta usar segun la dimensión de los archivos.
- Bases de datos espaciales
- Múltiples formatos: https://juliael.carto.com/
2.6.5 Programando con Big Data
- MapReduce: map, shuffle y reduce
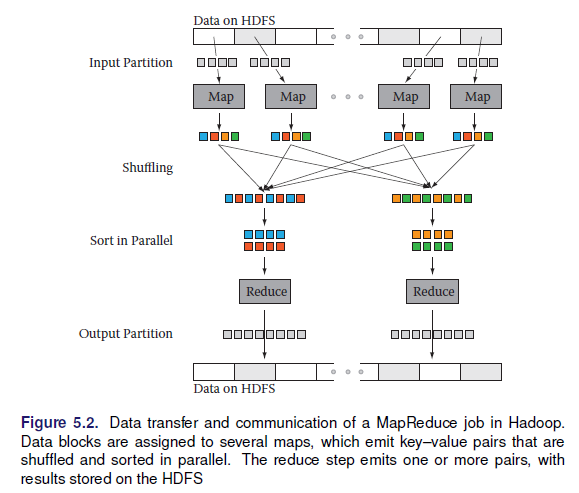
- Apache hadoop MapReduce (Hadoop Distributed File System HDFS)
- Apache Spark
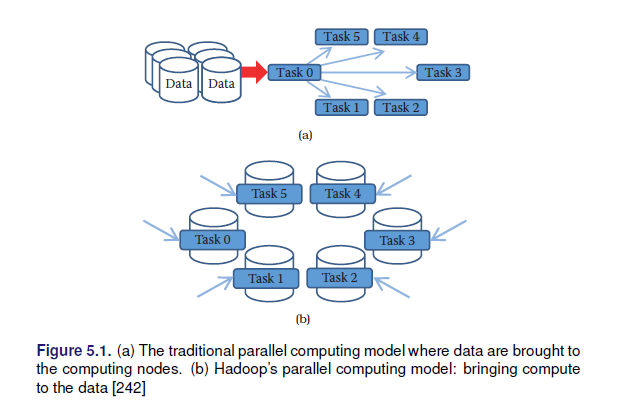
2.7 Análisis y modelado
2.7.1 Machine learning
¿Machine learning = Statistics?
Verán que muchos métodos discutidos a lo largo de su formación como estadísticos aparecen dentro del maching learning y que son llamados con otros nombres.
Al pensar en machine learning debemos asociarlo directamente con procesos computacionales, muchos otros conceptos giran al rededor de esta idea como la inteligencia artificial. Proceso de machine learning hoy:
- Permiten manejar autos de forma autónoma
- Puede recomendar libros, amistades, música, etc
- Identificar drogas, proteínas y ciertos génes
- Se usa para detectar ciertos tipos de cáncer y otras enfermedades médicas
- Ayudan a conocer que estudiantes necesitan un apoyo adicional
- Ayudan a persuadir por que candidato votar en las elecciones.
2.7.1.1 El proceso del machine learning
- Entender el problema y la meta
- Formular esto como un problema de machine learning
- Explorar y preparar los datos
- Feature engineeing
- Selección del método
- Evaluación
- Deployment
2.7.1.2 Formulación del problema
En ML existen 2 grandes categorías
Aprendizaje supervisado: Existe una \(Y\) que queremos predecir o clasificar a partir de los datos. El fin es el ajuste y la generalización * Clasificación (\(Y\) cualitativa) * Predicción * Regresión (\(Y\) cuantitativa)
Aprendizaje no supervisado: No existe una variable objetivo, se quiere conocer, entender las asociaciones y patrones naturales en los datos. * Clustering * PCA, MCA
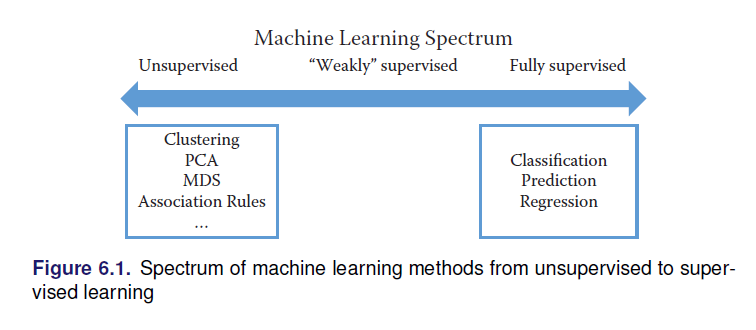
2.7.2 Análisis de texto: Entendiendo lo que la gente escribe
- Clasificación de documentos
- Análisis de sentimientos
- Etiquetado de discursos
2.7.3 Networks
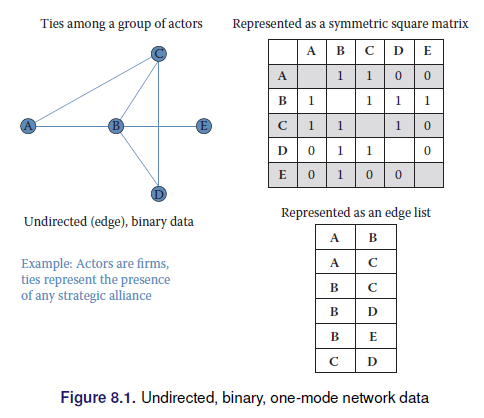
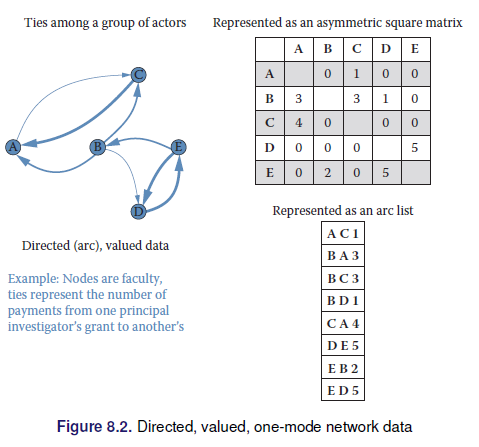
2.8 Inferencia y ética
2.8.1 Información y visualización
Los usuarios pueden escanear, reconocer, comprender y recordar representaciones visualmente estructuradas más rápidamente de lo que pueden procesar representaciones no estructuradas
La ciencia de la visualización se basa en múltiples campos, como la psicología perceptiva, las estadísticas y el diseño gráfico para presentar información
La efectividad de una visualización depende tanto de las necesidades de análisis como de los objetivos de diseño.
El diseño, el desarrollo y la evaluación de una visualización se guían por la comprensión de los antecedentes y las metas del público objetivo.
El desarrollo de una visualización efectiva es un proceso iterativo que generalmente incluye los siguientes pasos:
- Especificar las necesidades del usuario, tareas, requisitos de accesibilidad y criterios para el éxito.
- Preparar datos (limpiar, transformar).
- Diseñar representaciones visuales.
- Interacción de diseño.
- Planifique el intercambio de ideas, procedencia.
- Prototipo / evaluación, incluidas las pruebas de usabilidad.
- Implementar (supervisar el uso, proporcionar soporte al usuario, gestionar el proceso de revisión).
2.8.1.1 Dashboards
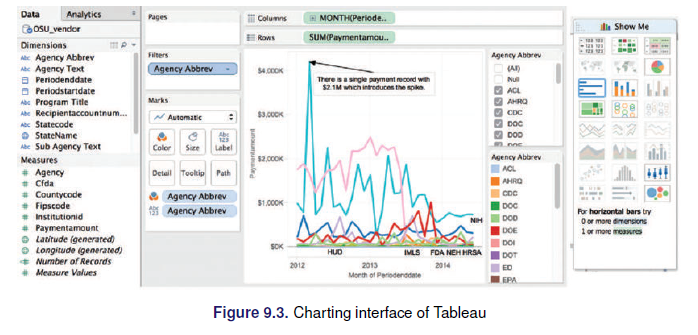
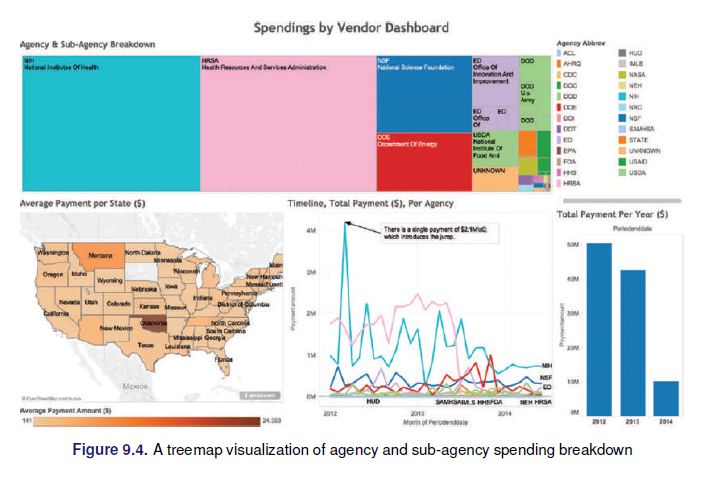
2.8.1.2 Elementos
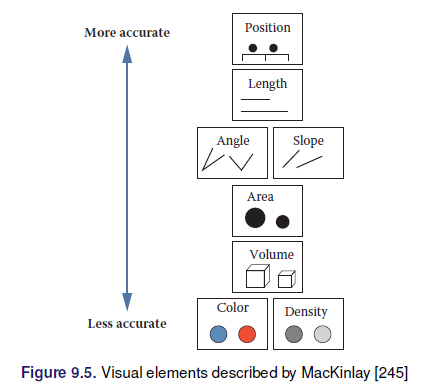
2.8.1.3 Datos espaciales
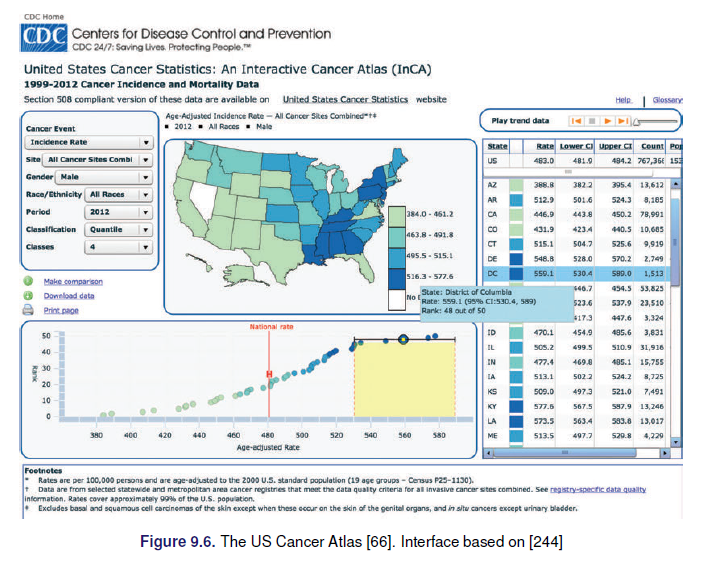
- Datos temporales
- Datos jerárquicos
- Datos de redes
- Datos de texto
Tarea: resumir los siguientes puntos del libro: Big Data and Social Science, Ian Foster.
2.8.2 Error e inferencia
2.8.3 Privacidad y confidencialidad
2.8.4 Workbooks
2.9 Ejercicios Propuestos
- Explorar los métodos cuasi-experimentales que existen
- Buscar información respecto a: los matriculados en educación regular y universidad por año y departamento en Bolivia
- Empleando la fuente anterior, generar en R el código que cargue el archivo encontrado
- Buscar dos papers (1) donde se uso machine learning y (2) análisis de texto y comentar con al menos 5000 caracteres
- Buscar ejemplos (al menos uno) de bases de datos, páginas web u otros asociados a datos que no respeten los principios de privacidad y confidencialidad.